Saat sedang menulis post terakhir mengenai Dekomposisi Nilai Singular, saya ingat bahwa dulu saat S1 saya pernah mengerjakan suatu projek kuliah yang berhubungan dengan SVD. Akhirnya, didorong oleh keinginan luhur, saya cari dan ketemulah di Google Drive. Waktu semester 7 di Bogor, saya mengambil mata kuliah Matematika Komputasi dimana ada tugas akhir yang harus dikerjakan berkelompok. Karena saya adalah ketua kelompok yang semena-mena, tentu saja dengan sebelah pihak saya memutuskan topik mengenai dekomposisi matriks dan aplikasinya bersama dengan 3 orang teman sekelompok.
Kita sepakat (saya sepakat dan teman-teman saya terpaksa) untuk mengambil satu bab dari buku yang direkomendasikan oleh dosen kami. Bab tersebut membahas mengenai SVD dan aplikasinya untuk pengenalan digit. Setelah saya lihat kembali, ternyata saya menggunakan R dan bukan Python dalam projek tersebut. Karena saya malas untuk porting, maka di tulisan ini saya akan menulis code tetap dalam bahasa R.
Table of Contents
Open Table of Contents
Pengenalan Data
Data yang kami gunakan adalah data berupa tulisan angka dalam bentuk matriks yang dapat diunduh di sini. Disana ada 4 buah file yang dapat di-download yaitu file train-images dan train-labels yang berisi 60.000 gambar berupa matriks dan juga label (digit 0-9) dari setiap gambar di data sebelumnya, dua file lainnya adalah test-images dan test-labels yang berisi 10.000 gambar matriks dan juga labelnya. Setiap gambar merupakan matriks berukuran yang merepresentasikan suatu digit. Contoh matriks yang merepresentasikan digit 1 sampai 3 ditunjukkan di bawah ini.

Tujuan dari projek ini adalah menggunakan Dekomposisi Nilai Singular untuk mendapatkan komponen utama dari setiap digit pada training data lalu menggunakan komponen-komponen utama setiap digit untuk memprediksi digit-digit pada test data dan lalu membandingkannya. Target kami awalnya adalah mendapatkan akurasi 80% atau lebih dengan menggunakan cara ini.
Digit Recognition
Secara garis besar yang kami lakukan adalah sebagai berikut:
- Data training kami bagi menjadi 10 kategori berdasarkan labelnya (digit 0-9).
- Untuk setiap kategori digit, kami buat sebuah matriks besar yang setiap kolomnya merepresentasikan satu buah digit tulisan tangan.
- Melakukan SVD pada setiap kategori digit (jadi ada 10 SVD yang dihasilkan).
- Ambil komponen utama setiap dari setiap SVD dengan jumlah yang sudah ditentukan sebelumnya.
- Untuk setiap gambar di test data, cari jaraknya ke komponen utama setiap kategori (jadi kita dapat 10 nilai jarak).
- Kita prediksi gambar itu sebagai digit dengan jarak terkecil dibandingkan kategori lainnya.
Step yang pertama dapat dilakukan dengan mudah. Step yang kedua dapat dijelaskan sebagai berikut: misal gambar yang kita miliki hanya berukuran maka akan kita buat vektor dengan panjang 9 seperti yang ditunjukkan di bawah ini.
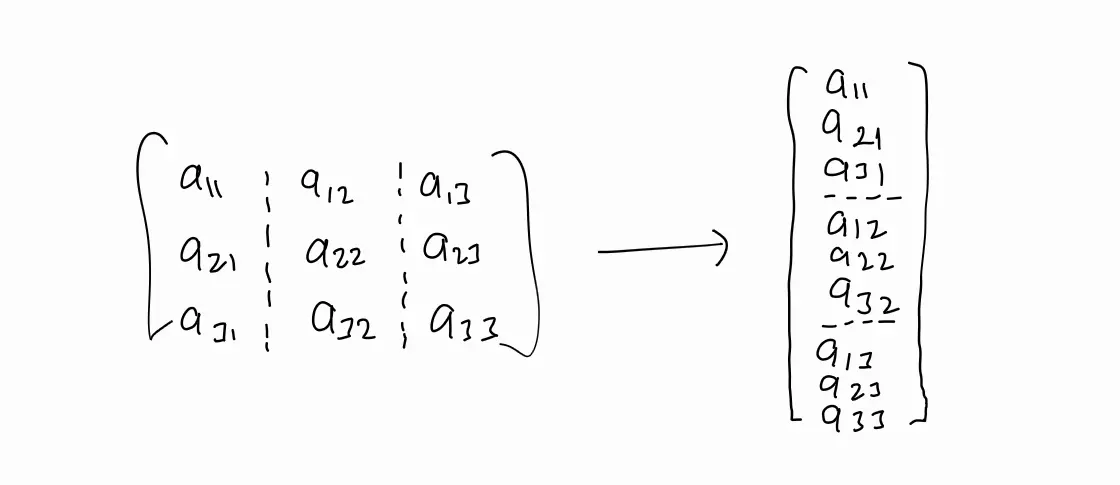
Sehingga jika, misal kita memiliki 1000 gambar dari suatu digit dan setiap gambar digit berukuran , maka kita akan memiliki suatu matriks berukuran (karena ).
Selanjutnya kita akan melakukan SVD pada setiap matriks yang kita peroleh sebelumnya. Ingat kembali bahwa SVD merupakan dekomposisi matriks menjadi dimana dan merupakan matriks dengan kolom ortonormal dan matriks diagonal dengan unsur-unsur diagonal bilangan positif dengan . Berkaitan dengan ruang kolom dan ruang baris dari , kita punya teorema berikut.
Misal memiliki dekomposisi nilai singular seperti yang disebutkan di atas. Maka
- Kolom-kolom dari matriks membentuk basis bagi ruang kolom matriks .
- Kolom-kolom dari matriks membentuk basis bagi ruang baris matriks .
Perhatikan bahwa kita menyusun sebuah matriks dimana kolom-kolomnya menyatakan gambar dari suatu digit. Sehingga kita bisa mengasumsikan bahwa ruang kolom dari matriks ini menyatakan ruang dari semua gambar digit tertentu dari data training. Akibatnya kolom-kolom dari matriks merupakan basis bagi ruang digit ini. Dengan mengambil beberapa vektor kolom dari yang bersesuaian dengan nilai singular yang besar, kita harapkan untuk mendapatkan vektor basis yang berpengaruh besar terhadap ruang digit tersebut. Pada kasus ini kita mengambil vektor pertama dari .
n <- 10
for (i in 0:9) {
digit_matrix <- train_images[,train_labels==i]
SVD <- svd(digit_matrix); SVD_list[[i+1]] <- SVD
U_truncated <- SVD$u[,1:n]
distance_matrix_list[[i+1]] <- diag(dim(train_images)[1])-U_truncated %*% t(U_truncated)
}Selanjutnya kita akan menjelaskan baris terakhir pada kode di atas. Kita sudah dapatkan suatu subruang yang kita harap dapat menjelaskan ruang dari suatu digit. Untuk suatu vektor gambar sebarang, kita akan menghitung jarak dari vektor tersebut ke masing-masing subruang (terdapat 10 subruang). Bagaimana cara mencari jarak dari suatu vektor ke subruang tertentu? Kita akan gunakan teorema-teorema berikut.
Misal suatu subruang tak-nol dari dan misal . Maka dapat ditulis sebagai dimana dan . Penulisan tersebut disebut dengan dekomposisi ortogonal dari dan vektor disebut dengan projeksi ortogonal dari pada .
dan
Misal suatu subruang tak-nol dari dan misal .
- Projeksi ortogonal pada , misal , adalah vektor di yang memiliki jarak terdekat .
- Jarak dari ke subruang adalah .
Perhatikan bahwa matriks yang kita peroleh dari hasil SVD merupakan suatu matriks dengan kolom-kolom ortonormal. Mencari projeksi ortogonal dari suatu vektor pada subruang berupa ruang kolom suatu matriks diberikan di bawah ini.
Misal merupakan matriks dengan kolom-kolom yang bebas linear dan misal ruang kolom dari matriks . Maka invertibel dan projeksi ortogonal dari pada adalah .
(Rasanya pernah liat ekspresi dimana ya???) Karena matriks yang kita miliki merupakan matriks dengan kolom-kolom ortonormal, maka projeksi ortogonal dari pada ruang kolom adalah . Sehingga jarak dari suatu vektor ke ruang kolom dari adalah . Hal ini menjelaskan pengambilan matriks pada kode di atas.
Sehingga sekarang untuk setiap vektor di test data, kita akan hitung nilai dari untuk . Setelahnya, kita ambil label hasil prediksi sebagai label dengan norma terkecil.
for (j in 1:dim(test_images)[2]) {
digit_vector <- test_images[,j]
min_distance <- 0
temp_label <- 0
# compute distance for each digit category
for (i in 0:9) {
distance <- norm(distance_matrix_list[[i+1]] %*% digit_vector)
if (i==0) {
min_distance <- distance
}
else if (distance < min_distance) {
min_distance <- distance; temp_label <- i
}
}
label_result[j] <- temp_label
}Bagian terakhir adalah bagian yang paling penting, yaitu menghitung akurasi. Apakah algoritma coba-coba yang kita buat ini cukup baik?
accuracy <- mean(label_result==test_labels)
print(paste("The accuracy is", accuracy))Dari hasil komputasi kami mendapatkan akurasi atau , lebih baik dari target kami. Tentu saja seperti sebelumnya, ini hanya suatu projek sederhana mahasiswa dan tidak cukup baik digunakan di dunia nyata untuk digit recognition.
Kode lengkap bisa dilihat di sini. Thanks.
Referensi
- Lars Elden, 2007. Matrix Methods in Data Mining and Pattern Recognition.
- https://math.libretexts.org/Bookshelves/Linear_Algebra/Interactive_Linear_Algebra_(Margalit_and_Rabinoff)/06%3A_Orthogonality/6.03%3A_Orthogonal_Projection
- http://yann.lecun.com/exdb/mnist/
- https://en.wikipedia.org/wiki/MNIST_database